Compilers are complex software systems that translate high-level programming languages to instructions that hardware is able to execute. Modern compiler infrastructure, such as LLVM, has grown to become highly modular and reusable in being able to support a large number of programming languages/models and target hardware using the same intermediate representation (IR) infrastructure. The advent of specialized AI chips, however, presents new challenges in the process of compiler and IR design, as well as lowering such IR to hardware to realize high performance.
PolyMage Labs offers PolyBlocks, which are “blocks” that can be used to build compilers and code generators for high-performance computing. PolyBlocks can be viewed as a compiler engine that is highly reusable for optimization and mapping to parallel hardware, including custom accelerators.
Write high-level Python and obtain highly optimized GPU code fully automatically with our PolyBlocks compiler!
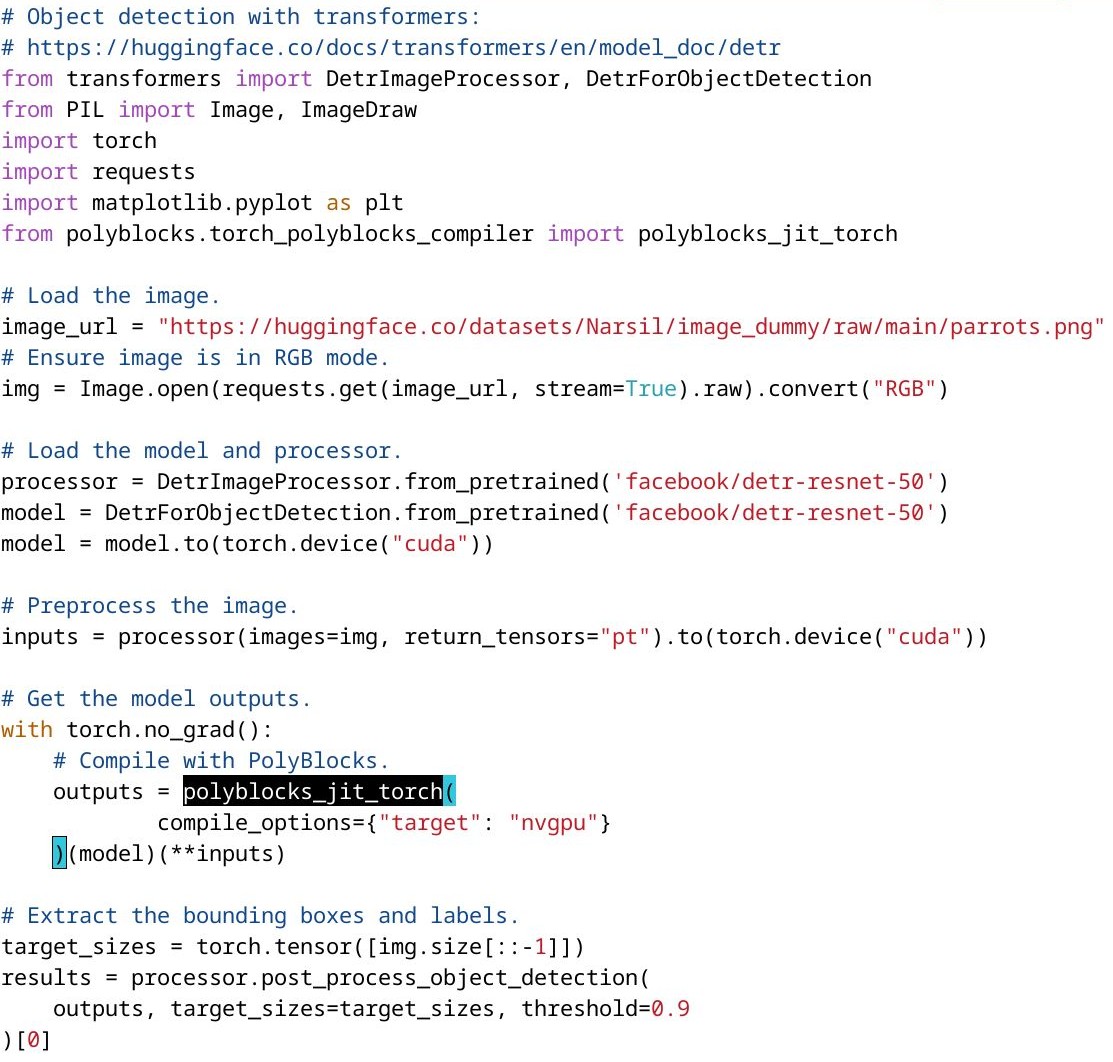
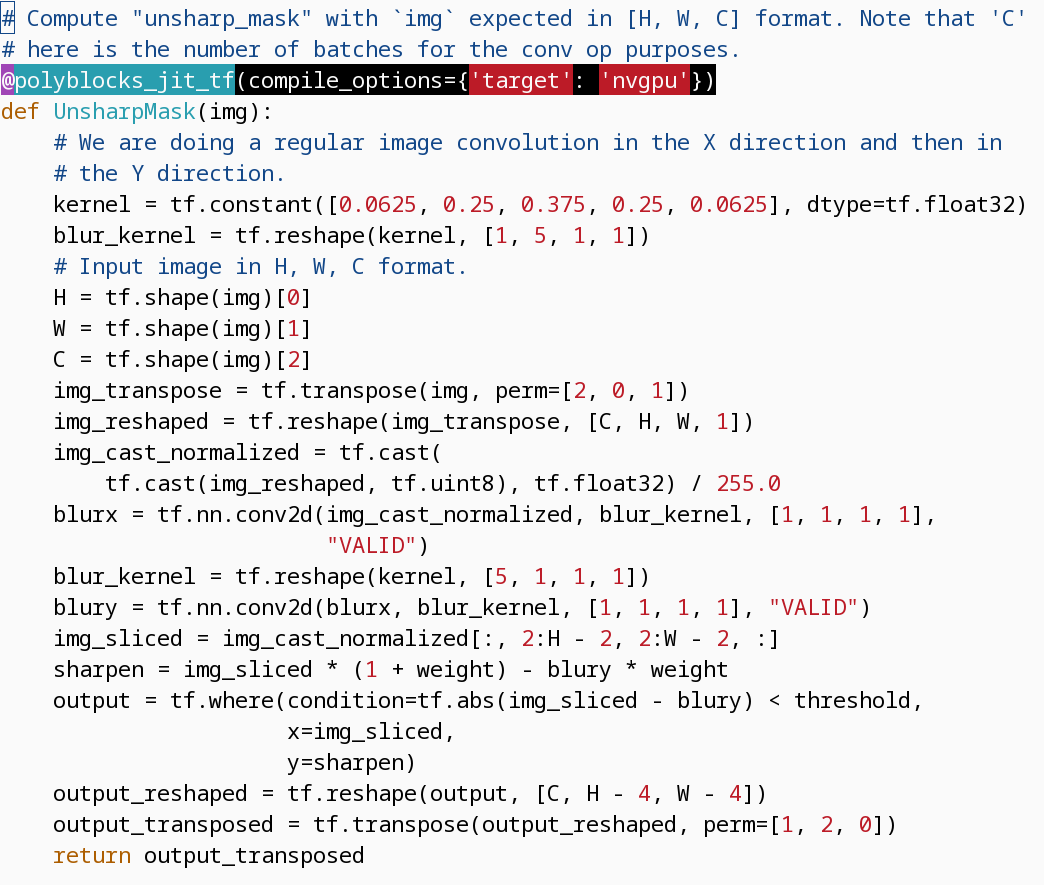
The PolyBlocks Compiler Engine
PolyBlocks is based on the MLIR infrastructure. It supports the popular AI programming frameworks like PyTorch, TensorFlow, and JAX, and multiple hardware targets including CPUs, NVIDIA GPUs, AMD GPUs, and Tenstorrent chips. PolyBlocks uses a combination of techniques on SSA and polyhedral optimization (where applicable) and is particularly powerful for computations on high-dimensional data spaces (tensors). Its optimization techniques encompass tiling, fusion, performing recomputation (in conjunction with tiling and fusion), packing into on-chip buffers for locality, eliminating intermediate tensors or shrinking intermediate tensors to bounded buffers fitting into on-chip memory, mapping to matmul/tensor cores, and efficient parallelization in a way unified with all other transformations. Its code generation pipeline includes the above-mentioned optimization techniques packaged into “compiler passes” or utility libraries. It can thus be easily used to build new PolyBlocks-powered compilers for new hardware or new programming frameworks.
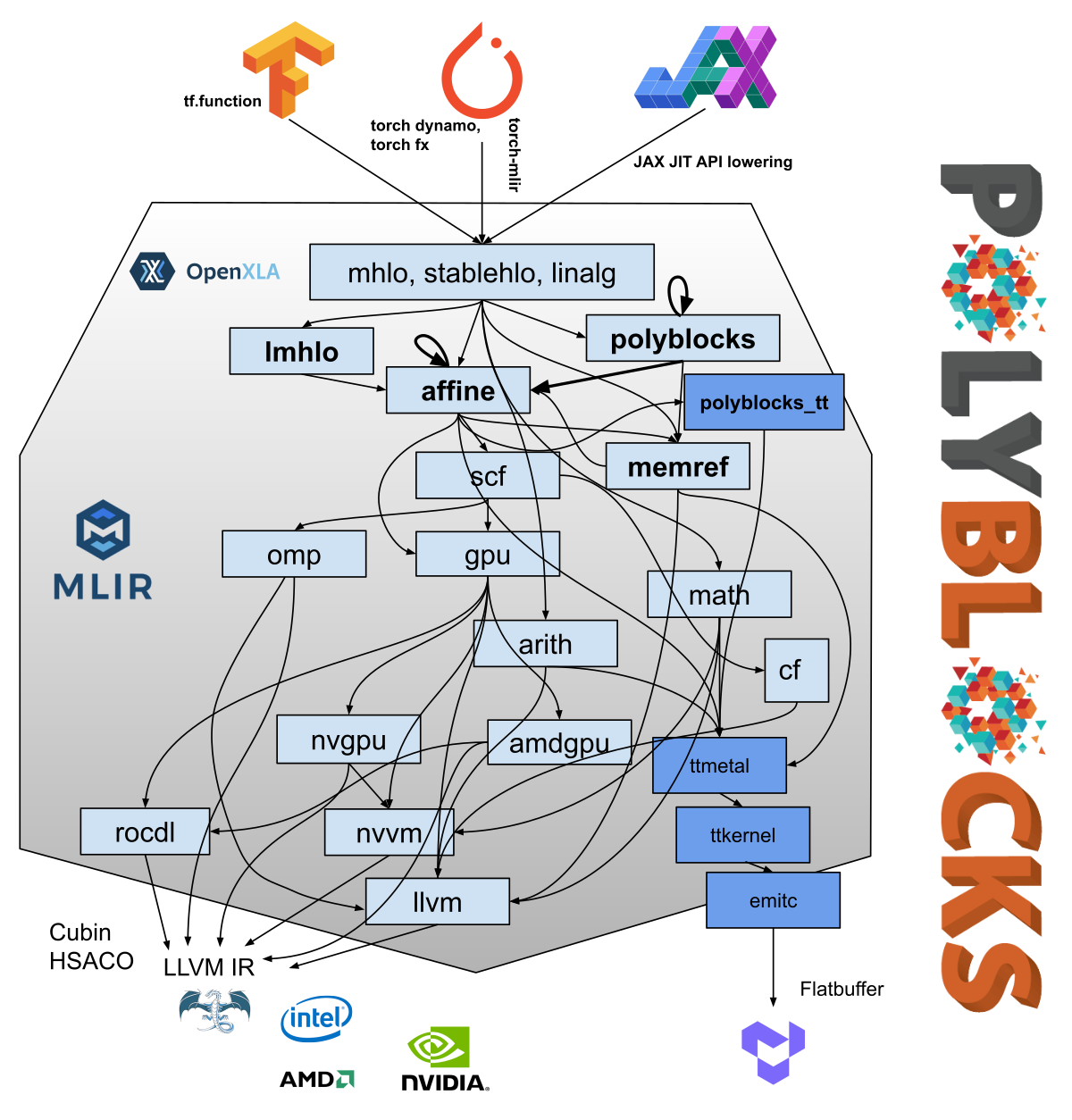
PolyBlocks already supports CPUs, NVIDIA GPUs, AMD GPUs, and Tenstorrent chips as hardware targets, and the PyTorch, TensorFlow, and JAX programming frameworks. More information can be found at the PolyBlocks documentation site. A glimpse of PolyBlocks’ performance with various frameworks can also be found on our Twitter handle and our LinkedIn handle.
PolyBlocks can be used in just-in-time (JIT) and ahead-of-time (AOT) compilation modes. It can thus be used to generate high-performance libraries for offline use. This approach makes the development of highly-tuned, commonly-used routines more modular and scalable, reducing the time necessary to create a version that achieves machine peak performance. Using compiler infrastructure also reduces the time required to realize the best version if something in the hardware or computation patterns were to change.
The PolyBlocks compiler engine features numerous reusable and extensible transformation passes, along with new operations and their associated infrastructure. Most of the mid-level transformations and optimizations are based on the MLIR affine and memref dialect infrastructure. They are highly reusable across various domains served by dense matrix/tensor computations, such as deep learning, image processing pipelines, stencil computations, and similar ones used in science and engineering.
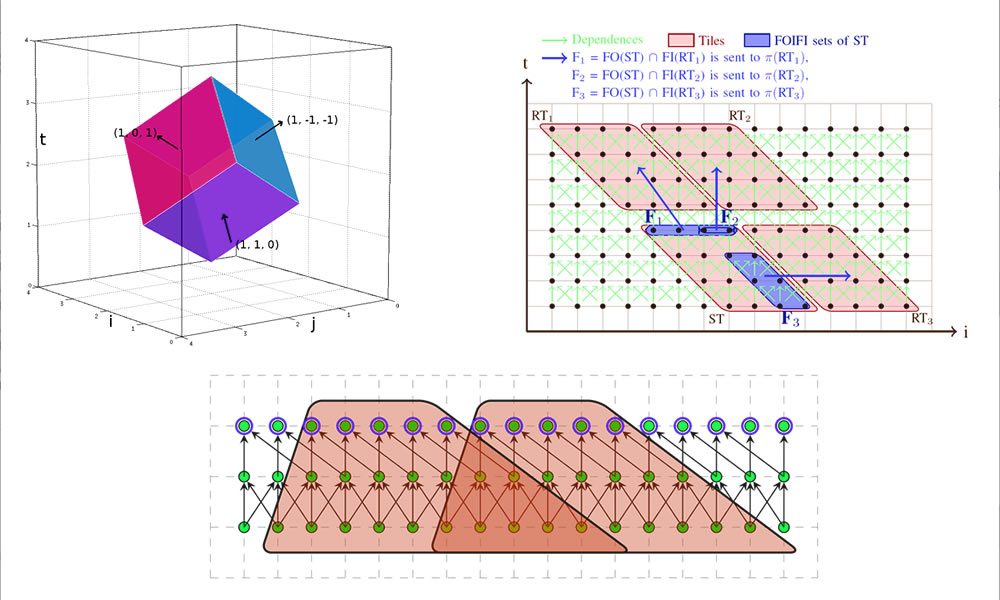
The example to the right shows how one can obtain near-peak performance on matrix-matrix multiplication (GEMM) entirely using automatic code optimization and generation infrastructure through a compact IR specification. The specification on the right realizes a highly complex schedule established to be state-of-the-art (more details here). The snippet shows how powerful code transformation directives can be encoded in a compact manner: these include polyhedral scheduling encoding multi-level tiling, loop interchange, unroll-and-jam / register tiling, and vectorization, letting the code generation infrastructure emit several thousands of lines of highly optimized code.

A Glimpse of PolyBlocks Compiler Performance

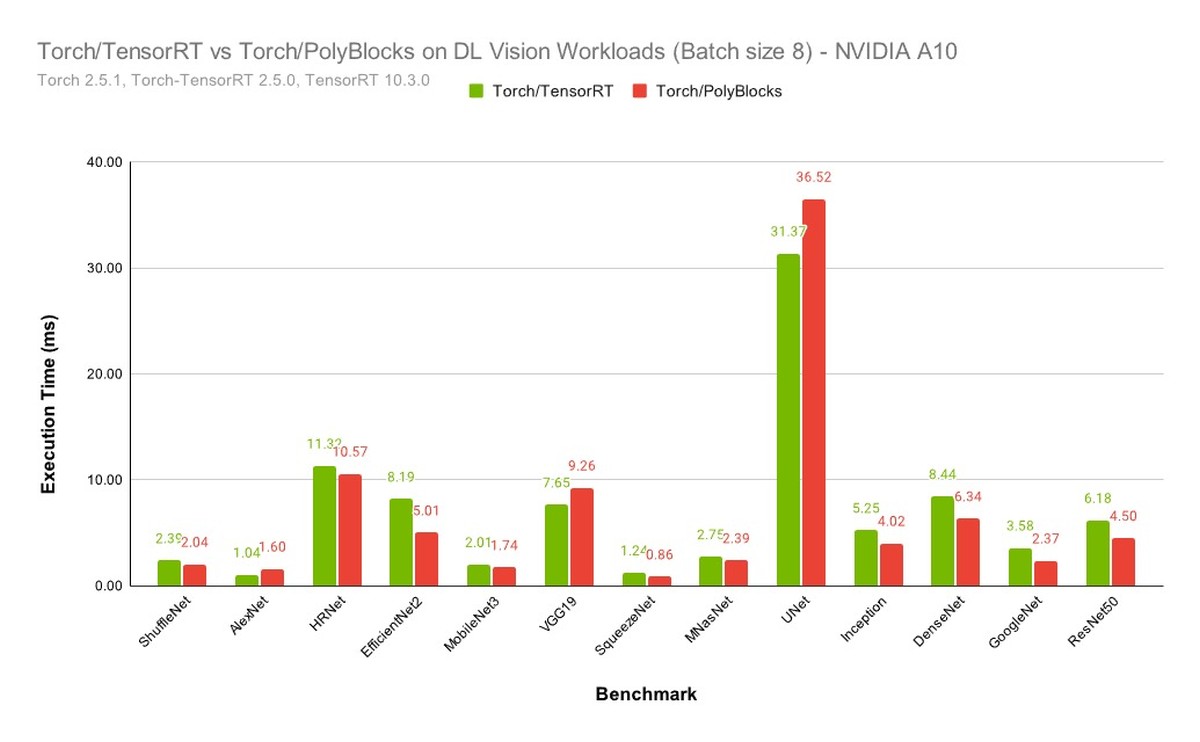
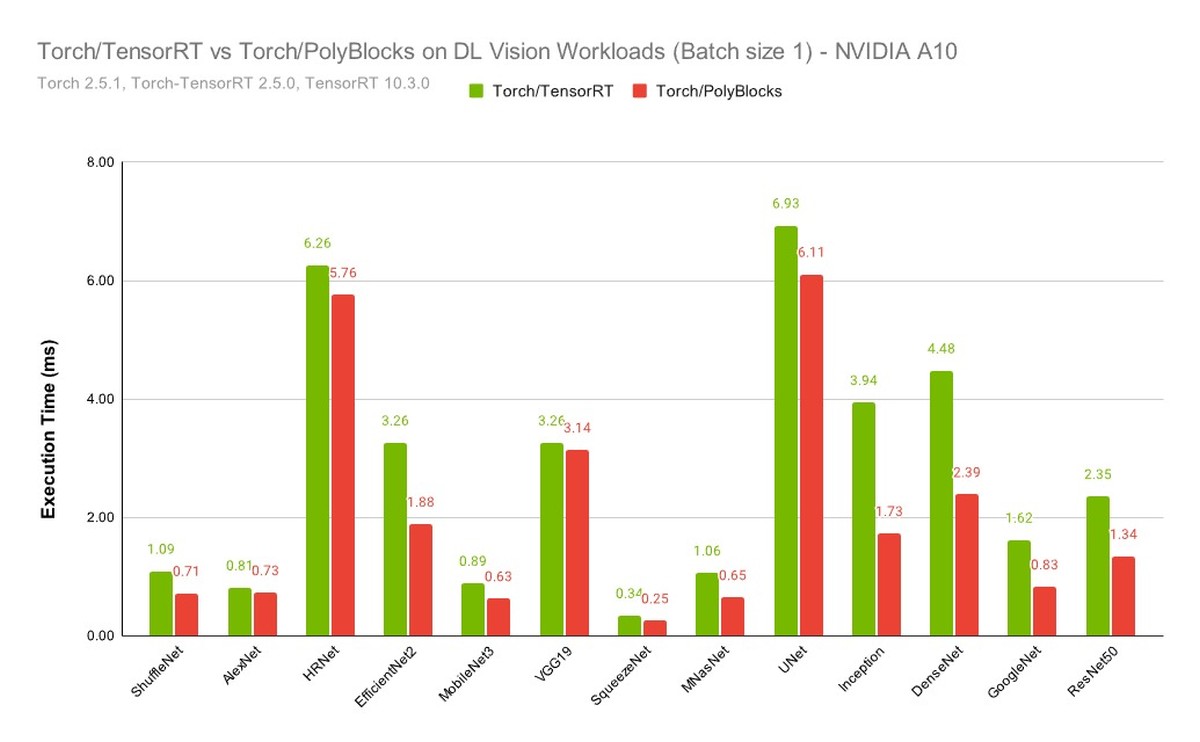


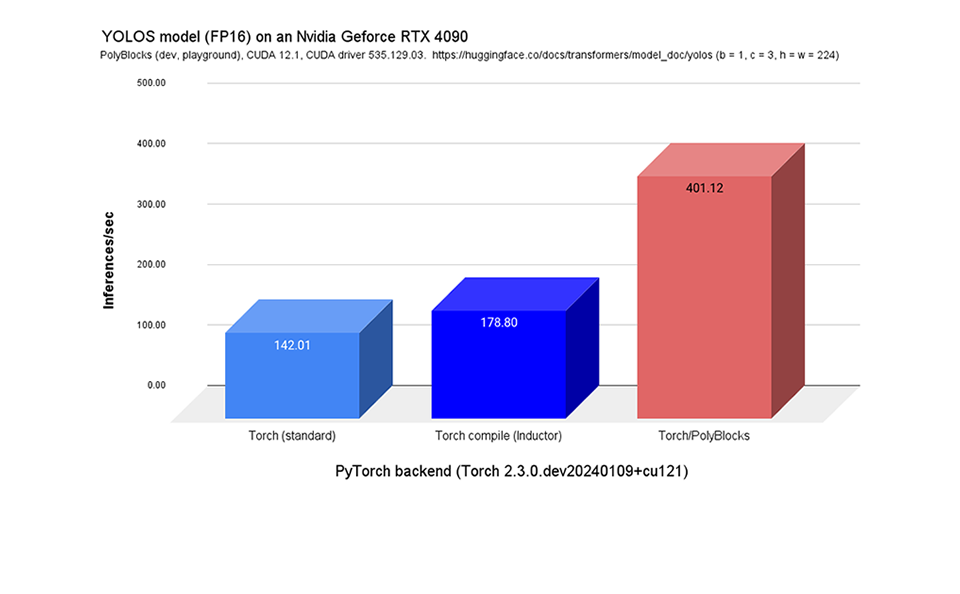
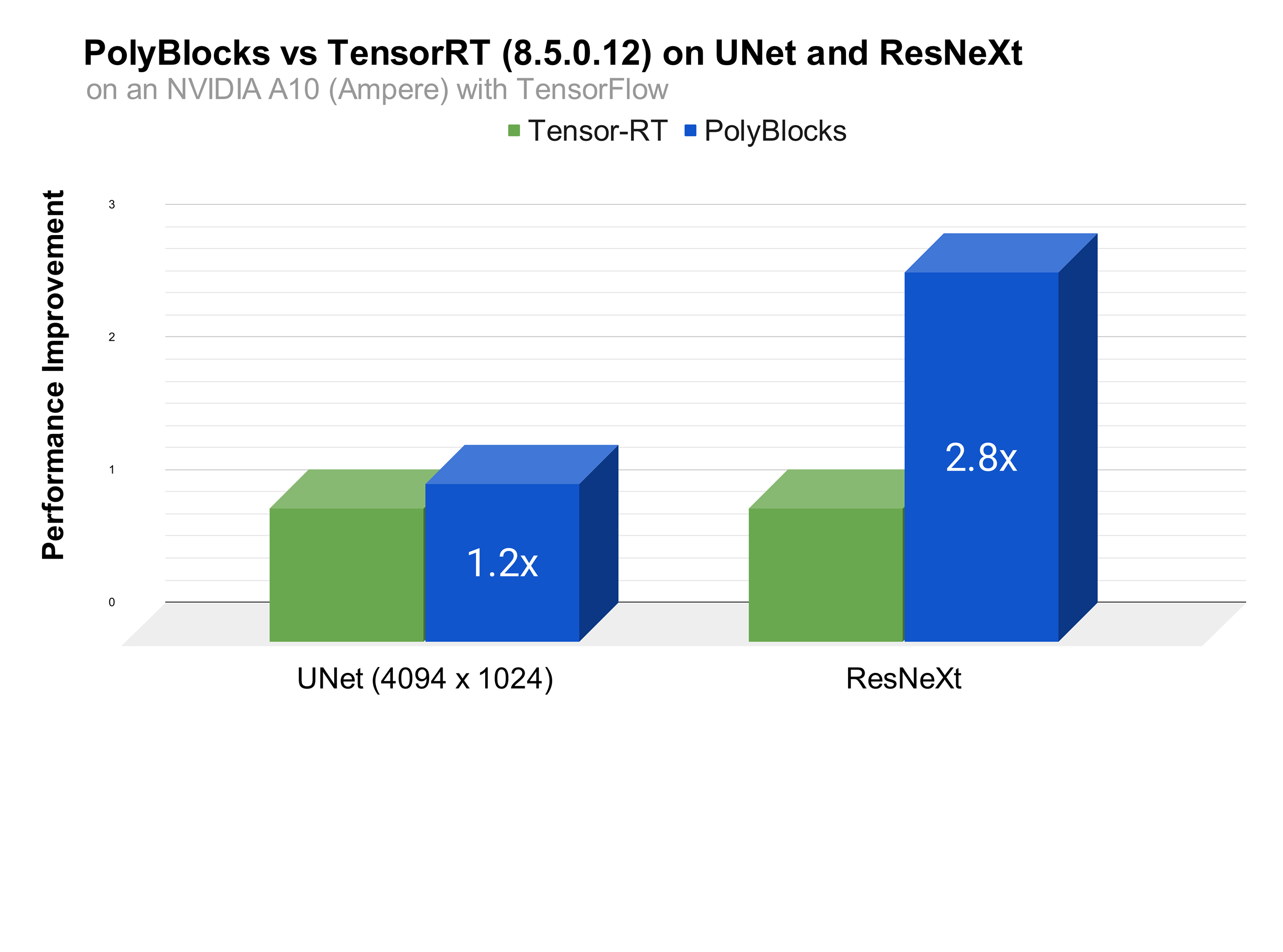


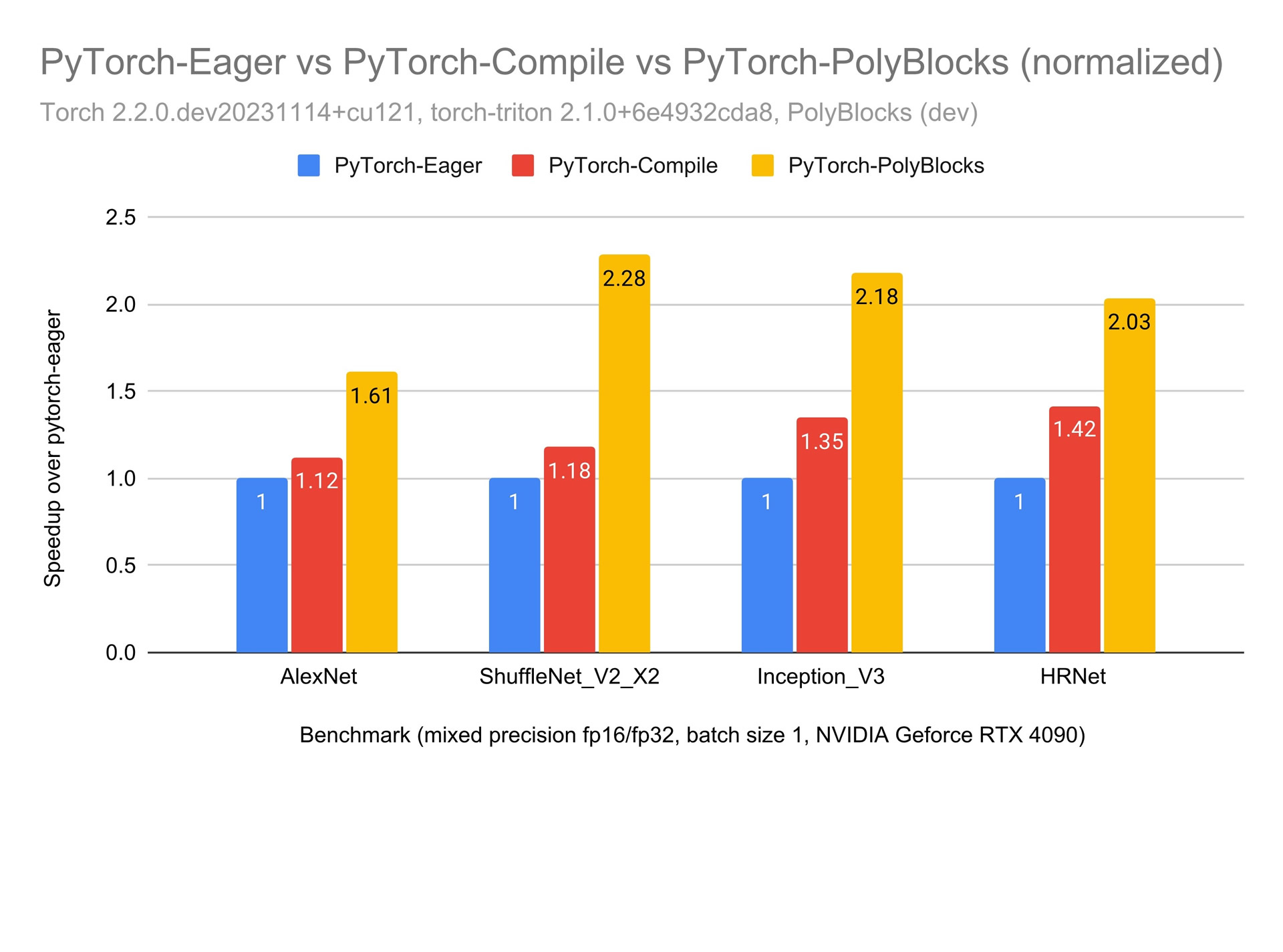
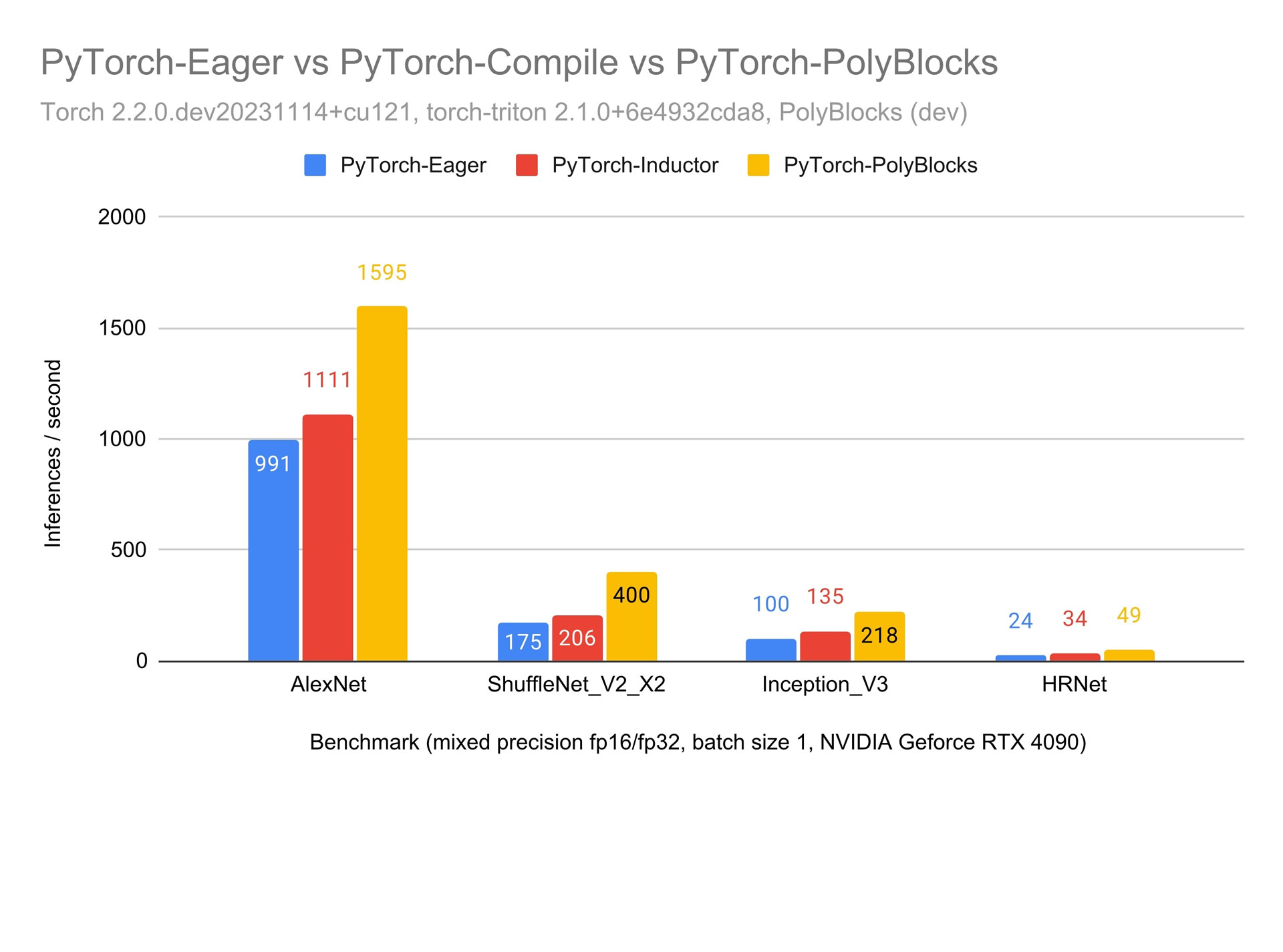

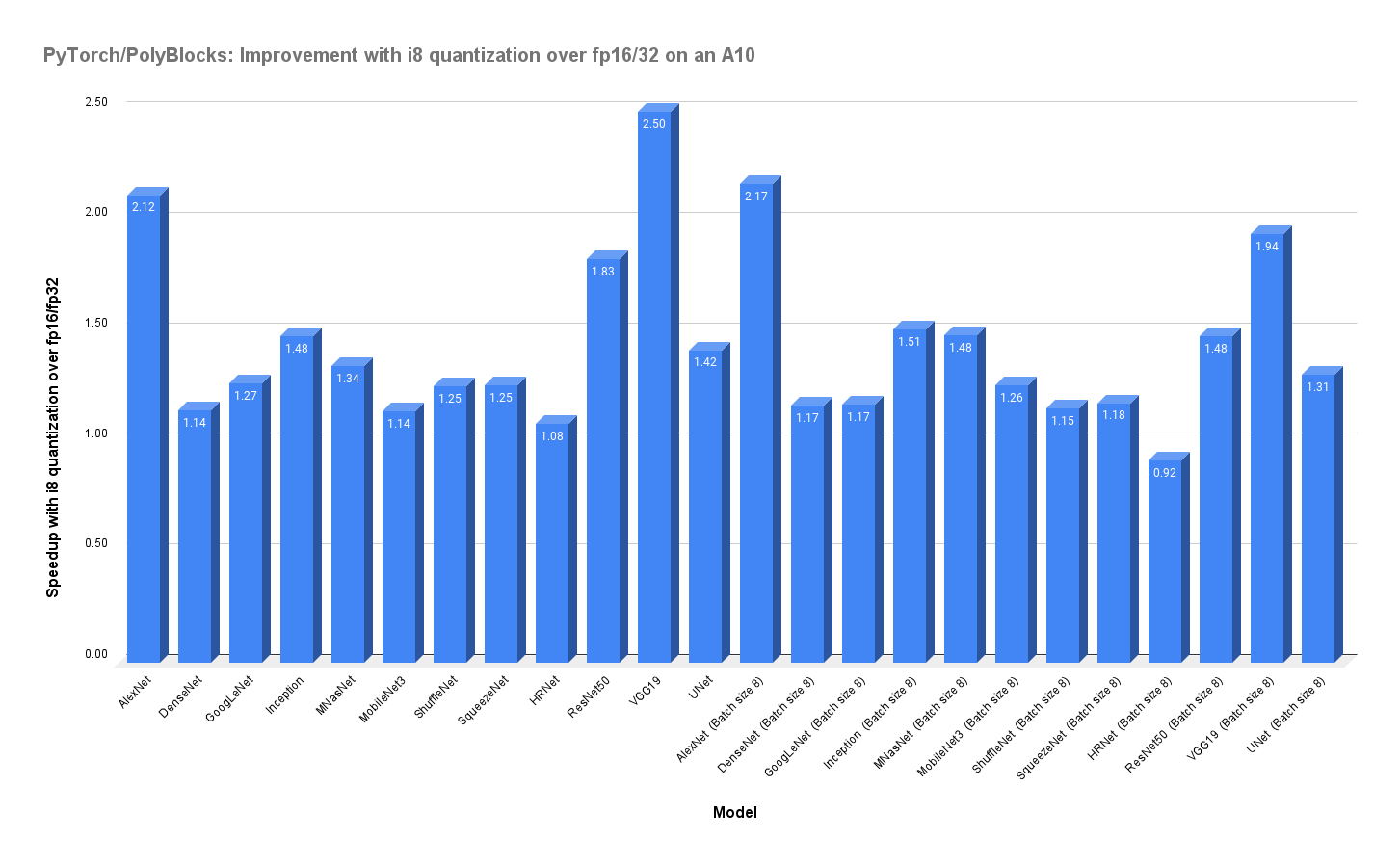
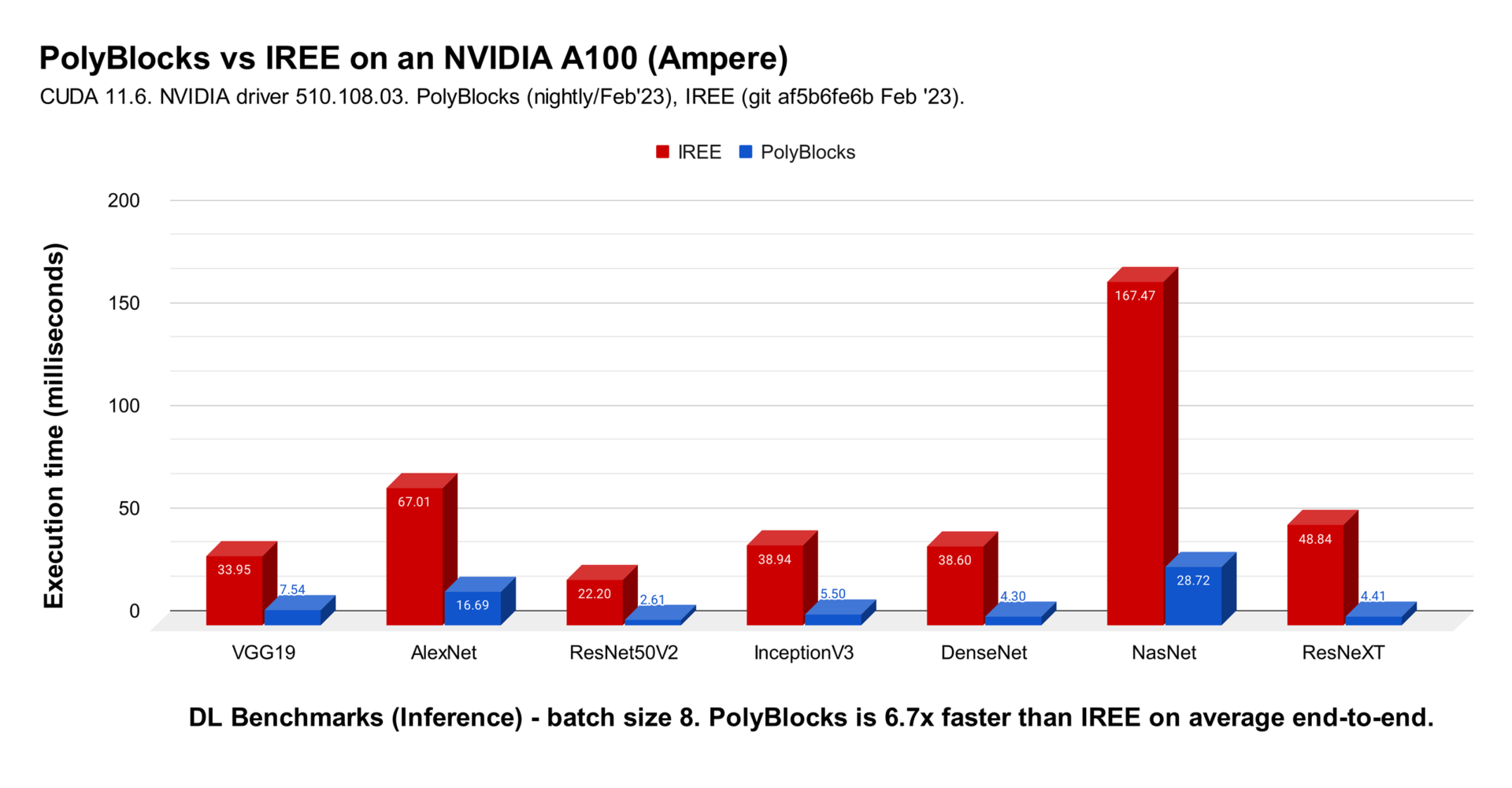
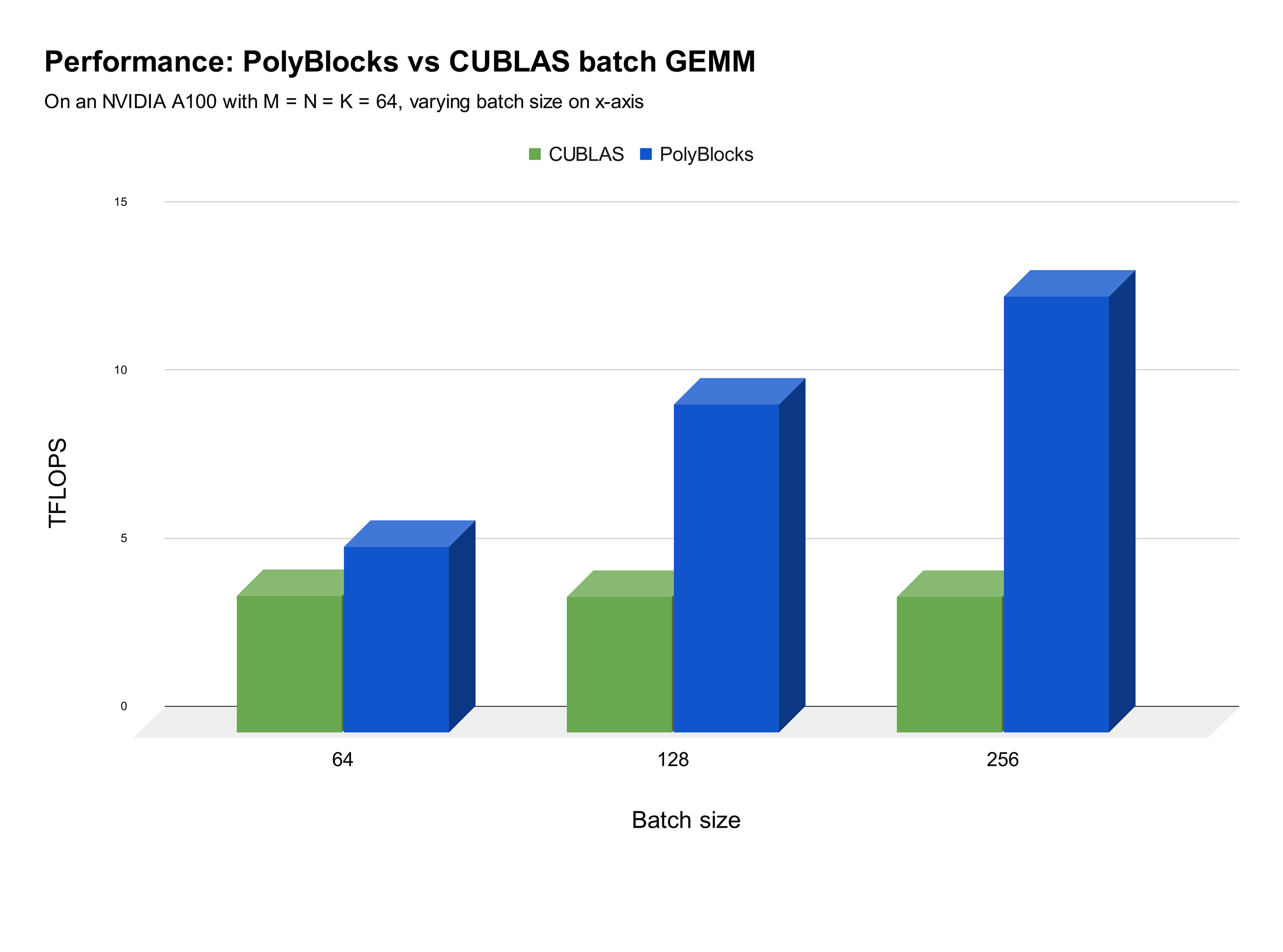


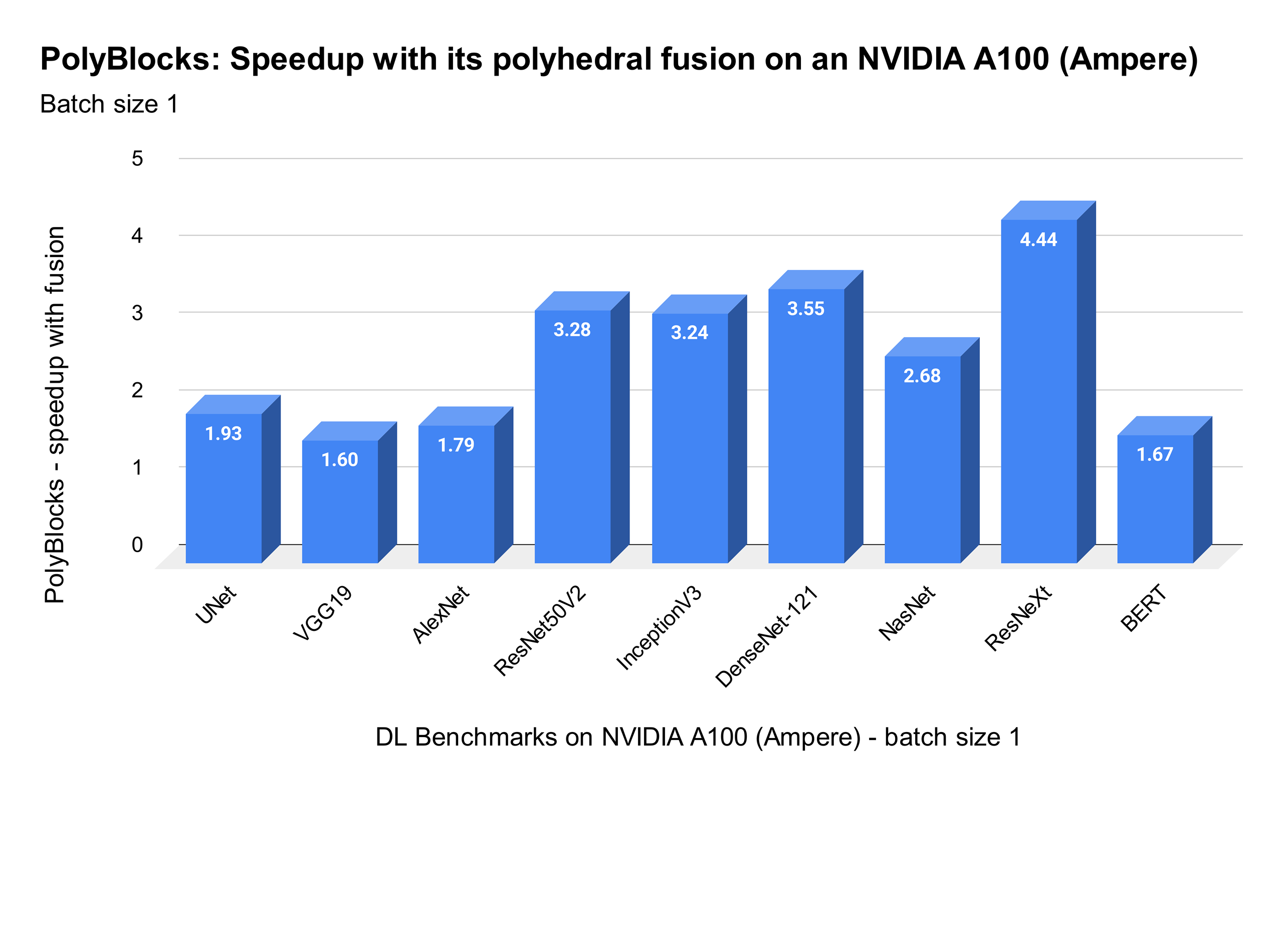
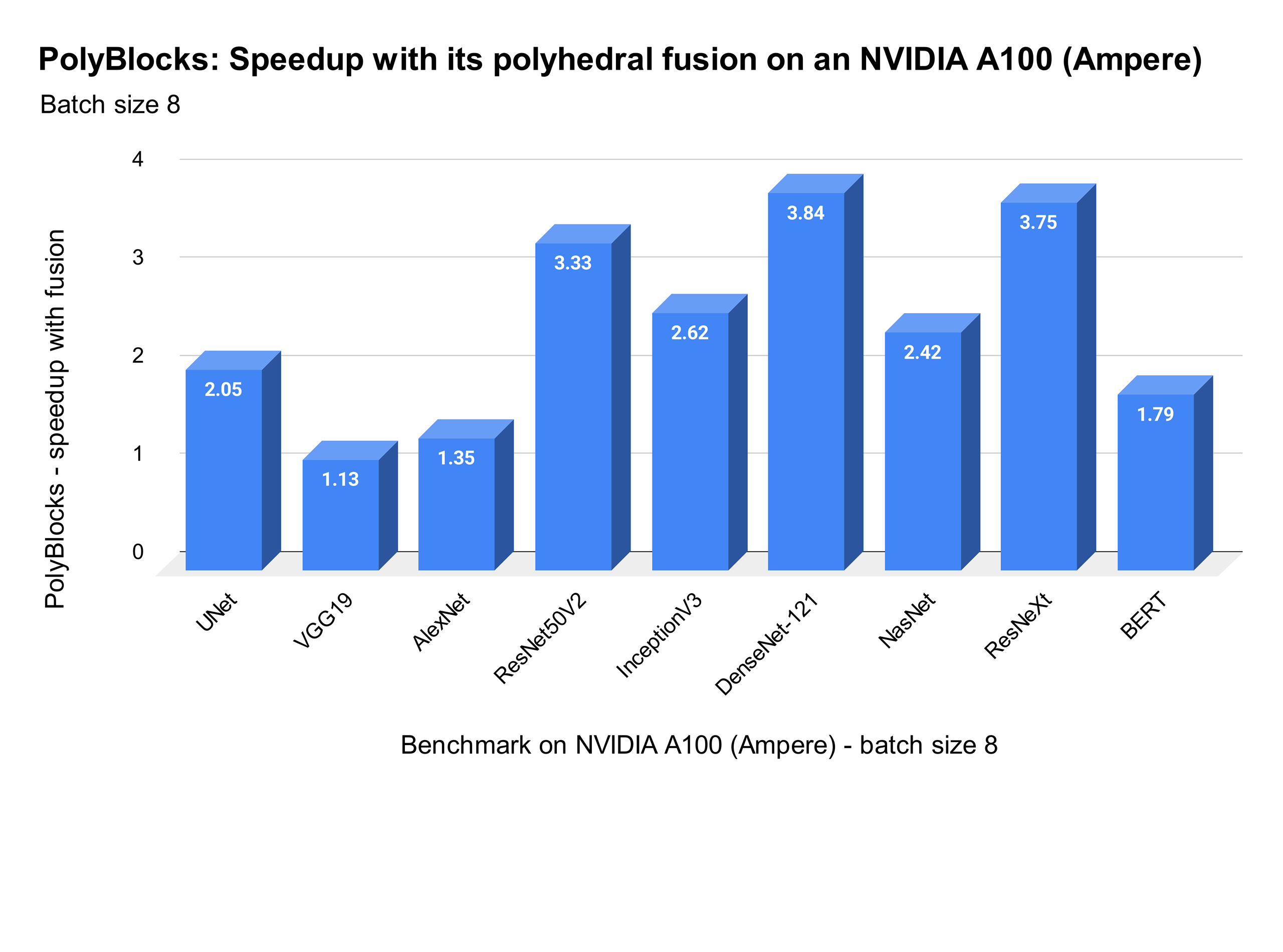

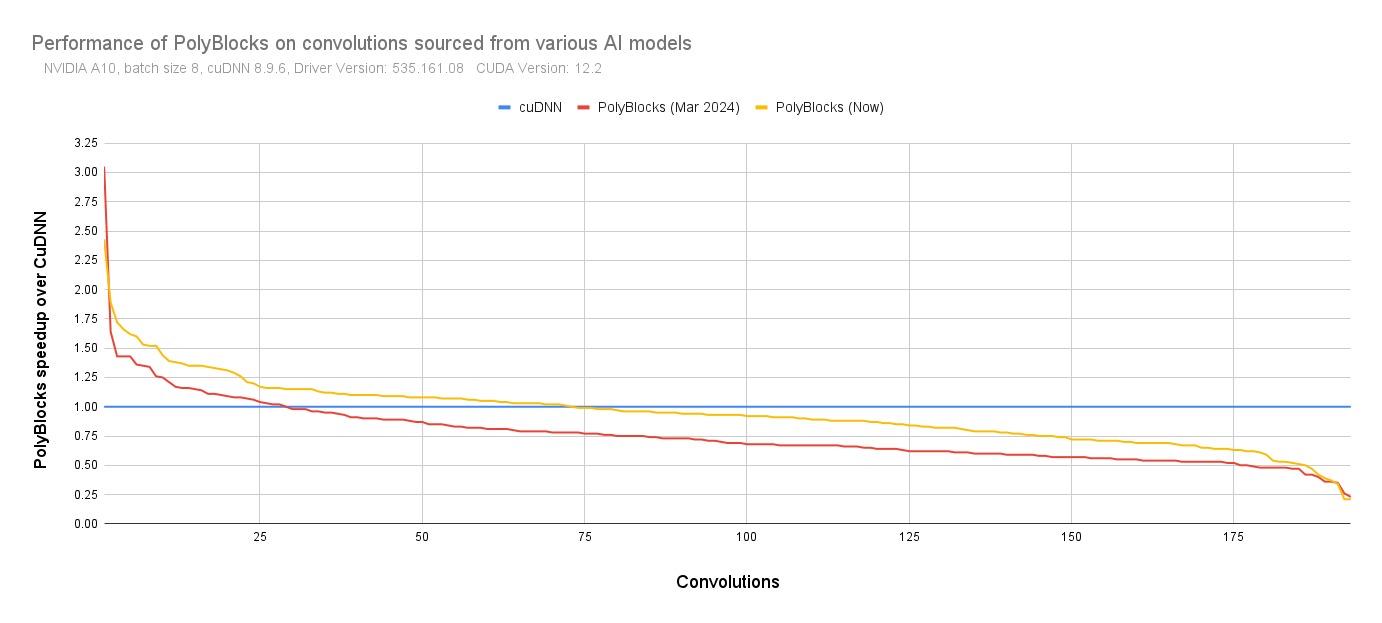
We strongly believe that automatic code generators have a large role to play in the development of some of the most critical primitives used in deep learning. Performance obtained through MLIR-based automatic code generators can not only compete with but also surpass that achieved by expert hand-written and tuned libraries. The experimental plot below shows one scenario where significant improvements were obtained with de facto state-of-the-art vendor libraries on a state-of-the-art accelerator. Using an automatic code generation approach also allows teams to develop and optimize libraries for deep learning models to be more productive while achieving near-machine-peak performance.
Expertise
The team at PolyMage Labs distinguishes itself through its deep and specialized expertise at the intersection of the polyhedral framework, high-performance computing, and MLIR. Its expertise and skills were acquired from academic research as well as from the creation of and continued involvement in a number of open-source compiler projects and tools based on the polyhedral framework.
PolyMage Labs’ engineers actively contribute to open-source ML/AI compiler projects, notably MLIR and TensorFlow/MLIR, upstreaming code to their repositories and participating in their online design discussions and forums. Much of our engineering and development work continues to benefit, and benefit from, state-of-the-art upstream MLIR infrastructure, being in sync with its codebase and community.
Engaging with us
If you are a hardware vendor building specialized chips for Artificial Intelligence and are interested in exploring our products or services for your software/compiler stack, please do reach out to us. Alternatively, if your business is driven by ML/AI algorithms and you are looking for a productive and performant path to acceleration on state-of-the-art AI accelerator hardware, such as NVIDIA GPUs, PolyBlocks can have a dramatic impact. Please see the FAQ on using, trying, or licensing PolyBlocks.
Testimonials

We partnered with PolyMage Labs to solve core compiler technical challenges together using MLIR and its polyhedral abstractions. PolyMage Labs, with its unique and internationally recognized leading expertise in compiler infrastructure for ML/AI, was able to obtain highly promising results in a short period of time.